Advanced Usage
This page includes details about some advanced features that Intel Owl provides which can be optionally enabled. Namely,
Organizations and User management
Starting from IntelOwl v4, a new “Organization” section is available on the GUI. This section substitute the previous permission management via Django Admin and aims to provide an easier way to manage users and visibility.
Multi Tenancy
Thanks to the “Organization” feature, IntelOwl can be used by multiple SOCs, companies, etc…very easily. Right now it works very simply: only users in the same organization can see analysis of one another. An user can belong to an organization only.
Manage organizations
You can create a new organization by going to the “Organization” section, available under the Dropdown menu you cand find under the username.
Once you create an organization, you are the unique “Owner” of that organization. So you are the only one who can delete the organization and promote/demote/kick users. Another role, which is called “Admin”, can be set to a user (via the Django Admin interface only for now). Owners and admins share the following powers: they can manage invitations and the organization’s plugin configuration.
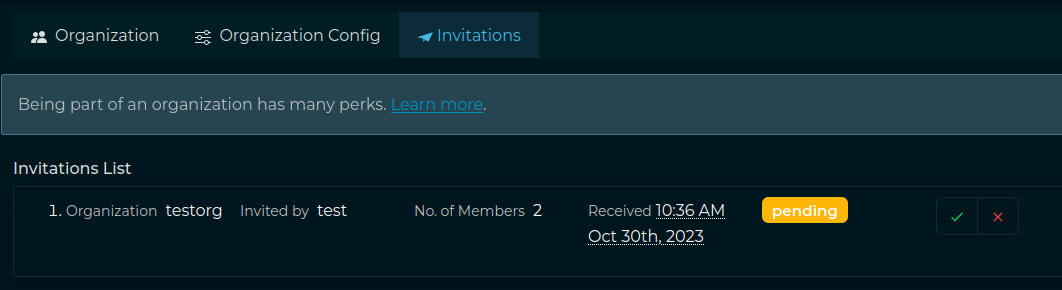
Accept Invites
Once an invite has sent, the invited user has to login, go to the “Organization” section and accept the invite there. Afterwards the Administrator will be able to see the user in his “Organization” section.
Plugins Params and Secrets
From IntelOwl v4.1.0, Plugin Parameters and Secrets can be defined at the organization level, in the dedicated section. This allows to share configurations between users of the same org while allowing complete multi-tenancy of the application. Only Owners and Admins of the organization can set, change and delete them.
Disable Plugins at Org level
The org admin can disable a specific plugin for all the users in a specific org. To do that, Org Admins needs to go in the “Plugins” section and click the button “Enabled for organization” of the plugin that they want to disable.

Registration
Since IntelOwl v4.2.0 we added a Registration Page that can be used to manage Registration requests when providing IntelOwl as a Service.
After a user registration has been made, an email is sent to the user to verify their email address. If necessary, there are buttons on the login page to resend the verification email and to reset the password.
Once the user has verified their email, they would be manually vetted before being allowed to use the IntelOwl platform. The registration requests would be handled in the Django Admin page by admins. If you have IntelOwl deployed on an AWS instance with an IAM role you can use the SES service.
To have the “Registration” page to work correctly, you must configure some variables before starting IntelOwl. See Optional Environment Configuration
In a development environment the emails that would be sent are written to the standard output.
Recaptcha configuration
The Registration Page contains a Recaptcha form from Google. By default, that Recaptcha is not configured and is not shown.
If your intention is to publish IntelOwl as a Service you should first remember to comply to the AGPL License.
Then you need to add the generated Recaptcha Secret in the RECAPTCHA_SECRET_KEY value in the env_file_app file.
Afterwards you should configure the Recaptcha Key for your site and add that value in the RECAPTCHA_SITEKEY in the frontend/public/env.js file.
In that case, you would need to re-build the application to have the changes properly reflected.
Optional Analyzers
Some analyzers which run in their own Docker containers are kept disabled by default. They are disabled by default to prevent accidentally starting too many containers and making your computer unresponsive.
| Name | Analyzers | Description |
|---|---|---|
| Malware Tools Analyzers |
|
|
| TOR Analyzers | Onionscan |
Scans TOR .onion domains for privacy leaks and information disclosures. |
| CyberChef | CyberChef |
Run a transformation on a CyberChef server using pre-defined or custom recipes(rules that describe how the input has to be transformed). Check further instructions here |
| PCAP Analyzers | Suricata |
You can upload a PCAP to have it analyzed by Suricata with the open Ruleset. The result will provide a list of the triggered signatures plus a more detailed report with all the raw data generated by Suricata. You can also add your own rules (See paragraph "Analyzers with special configuration"). The installation is optimized for scaling so the execution time is really fast. |
| PhoneInfoga | PhoneInfoga_scan |
PhoneInfoga is one of the most advanced tools to scan international phone numbers. It allows you to first gather basic information such as country, area, carrier and line type, then use various techniques to try to find the VoIP provider or identify the owner. It works with a collection of scanners that must be configured in order for the tool to be effective. PhoneInfoga doesn't automate everything, it's just there to help investigating on phone numbers. here |
To enable all the optional analyzers you can add the option --all_analyzers when starting the project. Example:
./start prod up --all_analyzers
Otherwise you can enable just one of the cited integration by using the related option. Example:
./start prod up --tor_analyzers
Customize analyzer execution
Some analyzers provide the chance to customize the performed analysis based on parameters that are different for each analyzer.
from the GUI
You can click on “Runtime Configuration”  button in the “Scan” page and add the runtime configuration in the form of a dictionary.
Example:
button in the “Scan” page and add the runtime configuration in the form of a dictionary.
Example:
"VirusTotal_v3_File": {
"force_active_scan_if_old": true
}
from Pyintelowl
While using send_observable_analysis_request or send_file_analysis_request endpoints, you can pass the parameter runtime_configuration with the optional values.
Example:
runtime_configuration = {
"Doc_Info": {
"additional_passwords_to_check": ["passwd", "2020"]
}
}
pyintelowl_client.send_file_analysis_request(..., runtime_configuration=runtime_configuration)
PhoneInfoga
PhoneInfoga provides several Scanners to extract as much information as possible from a given phone number. Those scanners may require authentication, so they’re automatically skipped when no authentication credentials are found.
By default the scanner used is local.
Go through this guide to initiate other required API keys related to this analyzer.
CyberChef
You can either use pre-defined recipes or create your own as explained here.
To use a pre-defined recipe, set the predefined_recipe_name argument to the name of the recipe as
defined here. Else, leave the predefined_recipe_name argument empty and set
the custom_recipe argument to the contents of
the recipe you want to
use.
Additionally, you can also (optionally) set the output_type argument.
Pre-defined recipes
“to decimal”:
[{"op": "To Decimal", "args": ["Space", False]}]
Analyzers with special configuration
Some analyzers could require a special configuration:
GoogleWebRisk: this analyzer needs a service account key with the Google Cloud credentials to work properly. You should follow the official guide for creating the key. Then you can populate the secretservice_account_jsonfor that analyzer with the JSON of the service account file.ClamAV: this Docker-based analyzer usesclamddaemon as its scanner and is communicating withclamdscanutility to scan files. The daemon requires 2 different configuration files:clamd.conf(daemon’s config) andfreshclam.conf(virus database updater’s config). These files are mounted as docker volumes in/integrations/malware_tools_analyzers/clamavand hence, can be edited by the user as per needs, without restarting the application. Moreover ClamAV is integrated with unofficial open source signatures extracted with Fangfrisch. The configuration filefangfrisch.confis mounted in the same directory and can be customized on your wish. For instance, you should change it if you want to integrate open source signatures from SecuriteInfoSuricata: you can customize the behavior of Suricata:/integrations/pcap_analyzers/config/suricata/rules: here there are Suricata rules. You can change thecustom.rulesfiles to add your own rules at any time. Once you made this change, you need to either restart IntelOwl or (this is faster) run a new analysis with the Suricata analyzer and set the parameterreload_rulestotrue./integrations/pcap_analyzers/config/suricata/etc: here there are Suricata configuration files. Change it based on your wish. Restart IntelOwl to see the changes applied.
Yara:You can customize both the
repositoriesparameter andprivate_repositoriessecret to download and use different rules from the default that IntelOwl currently support.The
repositoriesvalues is what will be used to actually run the analysis: if you have added private repositories, remember to add the url inrepositoriestoo!
You can add local rules inside the directory at
/opt/deploy/files_required/yara/YOUR_USERNAME/custom_rules/. Please remember that these rules are not synced in a cluster deploy: for this reason is advised to upload them on GitHub and use therepositoriesorprivate_repositoriesattributes.
DNS0_rrsets_nameandDNS0_rrsets_data(DNS0 API):Both these analyzers have a default parameter named
directionthat is used to dispatch the type of query to run.The value
rightfor this parameter runs the query usingdataAPI parameter. Otherwise, if the parameter value isleftit runs the query using thenameAPI parameter.
This parameter should not be changed from default value.
Notifications
Since v4, IntelOwl integrated the notification system from the certego_saas package, allowing the admins to create notification that every user will be able to see.
The user would find the Notifications button on the top right of the page:
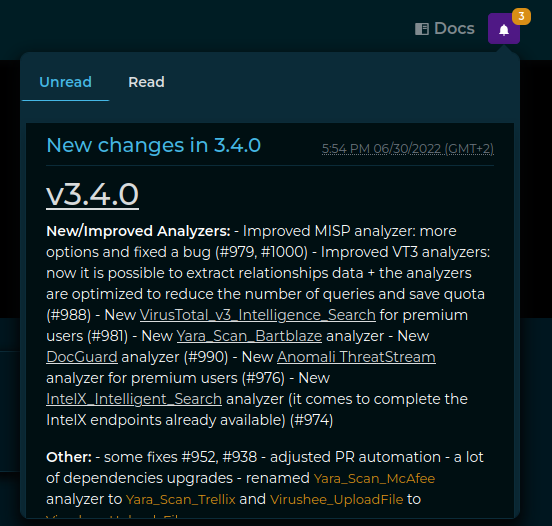
There the user can read notifications provided by either the administrators or the IntelOwl Maintainers.
As an Admin, if you want to add a notification to have it sent to all the users, you have to login to the Django Admin interface, go to the “Notifications” section and add it there.
While adding a new notification, in the body section it is possible to even use HTML syntax, allowing to embed images, links, etc;
in the app_name field, please remember to use intelowl as the app name.
Everytime a new release is installed, once the backend goes up it will automatically create a new notification, having as content the latest changes described in the CHANGELOG.md, allowing the users to keep track of the changes inside intelowl itself.